Import Details
Every collection or import in a repository has a details page. The details available will differ depending on the type of import.
To view details of an import collection
- Click the Action icon
 for the collection you want to view, then click Details.
for the collection you want to view, then click Details. - View the following information:
- Status
- Start Time
- Stop Time
- Elapsed
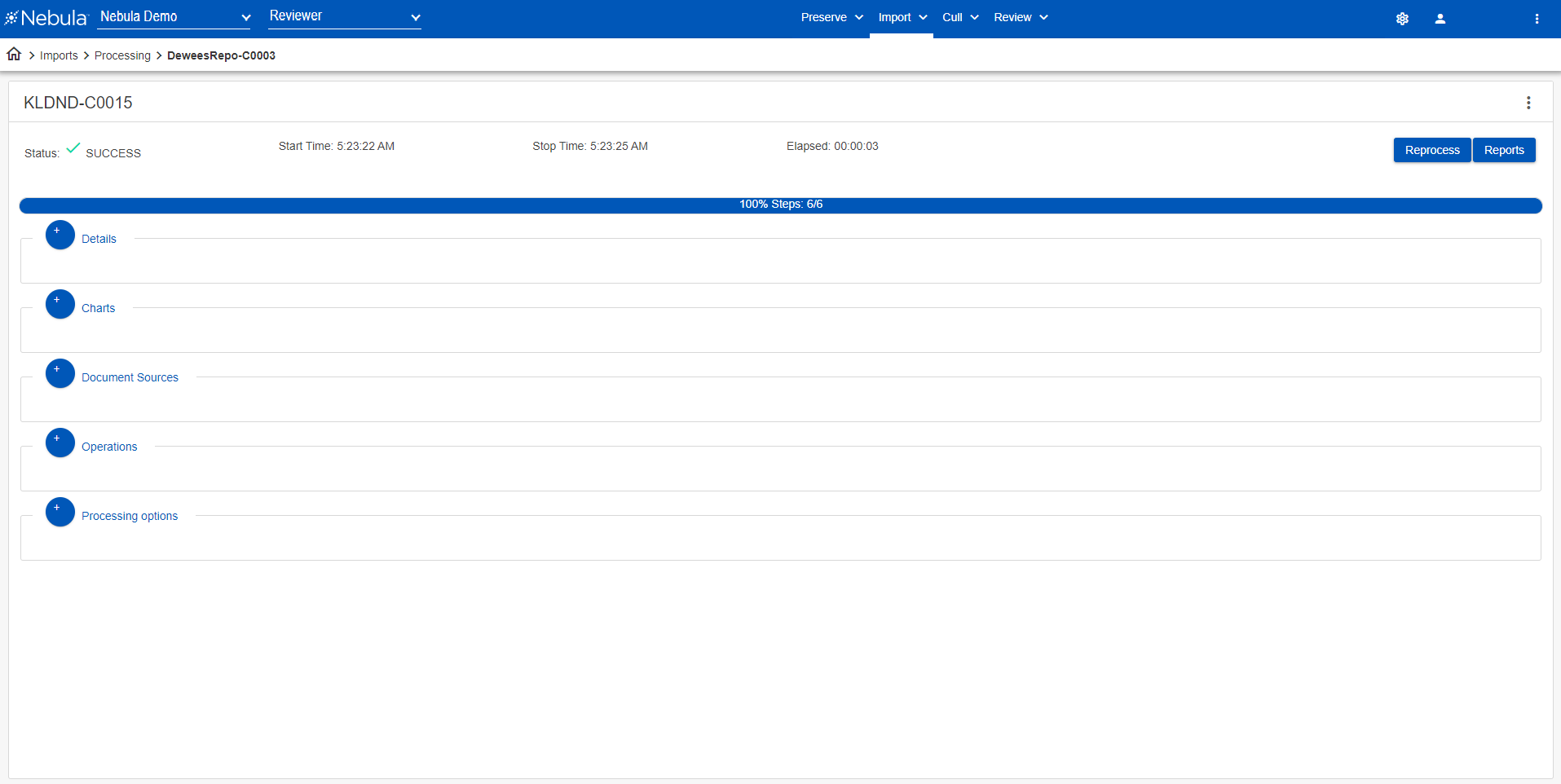
- Discovered: Number of files in input of collection.
- Exceptions: Number of exceptions during processing into Cull or a matter. (A report is available for these documents.)
- Input Size: Data size in GB of the original data size (compressed).
- Exploded: Number of documents present after extraction of compressed files, such as ZIPs and RARs, and including email attachments.
- NIST/Excluded: Number of deNISTed documents/number of excluded files (for example, JPGs <5kb, signature line images, and so on.)
- Output Size: Data size in GB of the uncompressed data.
- Processed: Number of total files processed (including containers, extracted documents, embedded documents and attachments).
- Need OCR: Number of documents flagged as having image layers without text.
- Duplicates: Document Count of family duplicates within the collection.
- Containers: Number of PSTs, ZIPs, RAR, other container files found in the data set.
- OCRed: Number of files sucessfully OCRed (whether within Nebula or imported from external application.)
- Exported Duplicates: Document count of family duplicates to data within the collection that have been exported.
- Extracted: Total number of documents extracted and searchable.
- Promoted to Review: Final number of documents promoted to the review matter.
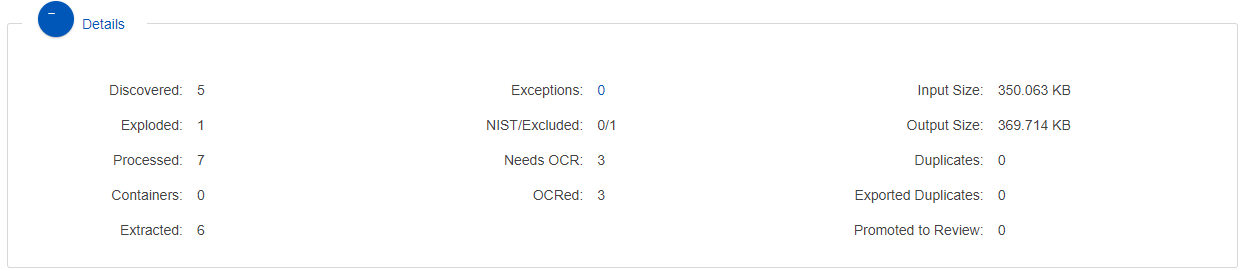
- Custodian Summary
- Doc Types Application Summary
- Path
- Custodian
- Output path
- Export Metadata
- Export Metadata
- HTML Applicable Files in the Collection
- Detect Language on the Collection
- Reindex Applicable Files in the Collection
- OCR Applicable Files in the Collection
- Export files that need OCR in the Collection
- Import files into Collection as OCR
- Named Entity Detection on the Collection
- Sentiment Analysis on the Collection
- Text Email Headers
- Max Spreadsheet Size
- Exclude Attached Images
- Use System Date
- De-NIST
- Ignore System Dates after Collection Date
- Explode Embedded
Collections - Processed Content contain the following information:
Details
Overview of documents located during the processing, as well as the number that were culled into Review.
Note: A document can have more than one exception for not processing.
Charts
Bar graph of documents imported into Nebula summarizing individual custodians and document types in a collection.
In case of any exceptions, the Exceptions Summary provides counts and types of exceptions that were recorded during the processing of the collection. Click CSV Report to generate and export an exceptions report.
Exceptions can be caused by improper paths in the load file, ID conflicts with existing documents, incomplete load files, or improper import settings.
The Nebula TechQ team can provide guidance regarding exception causes and recommend resolutions.

Document Sources
This provides the content source path, corresponding custodian assignment for each path, and an output path for the data in the collection.
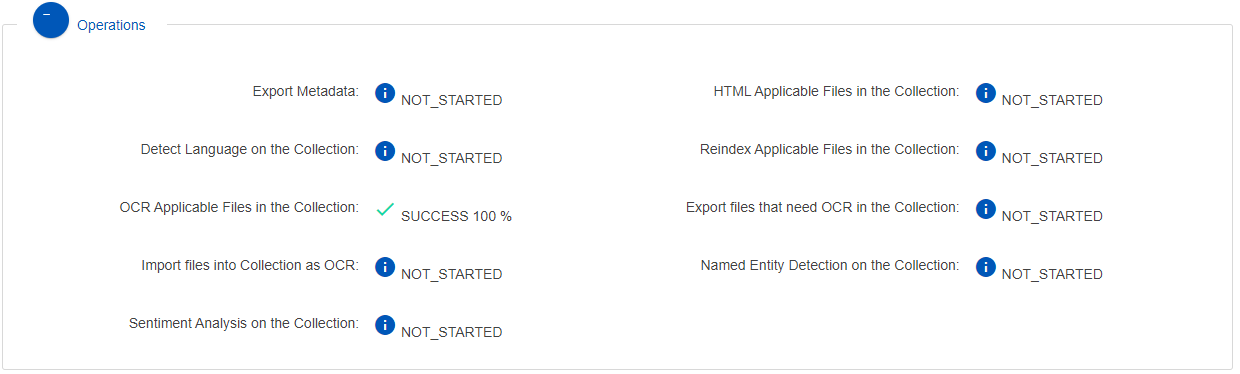
Operations
This shows the status of post-processing operations performed on a collection.
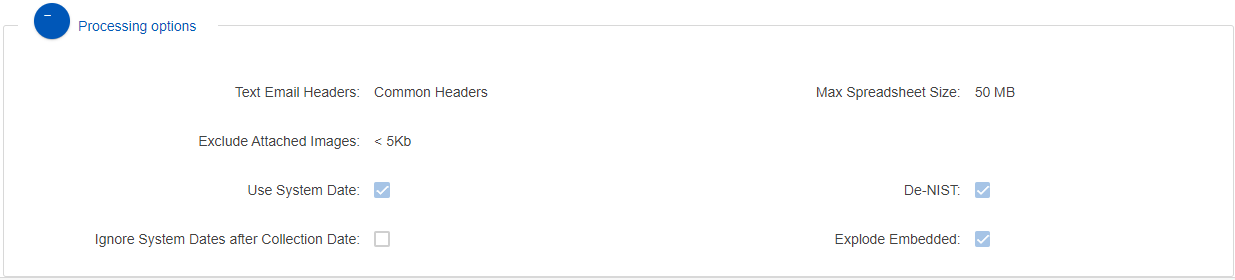
Processing options
This shows the options that were selected for the processing of the collection.
Third-party Imports contain the following information:
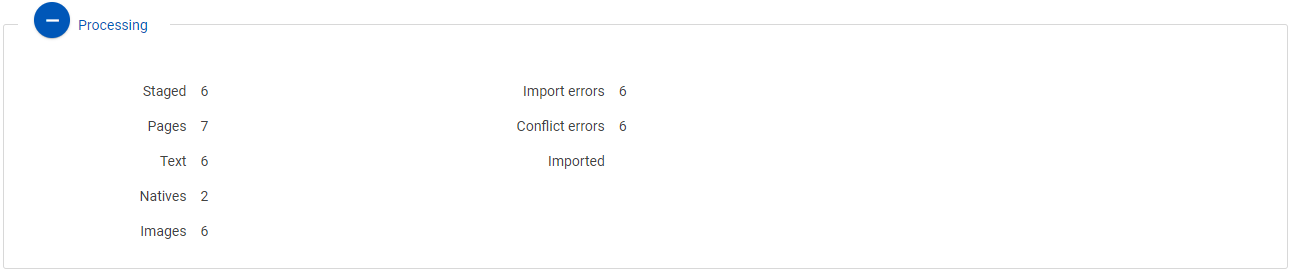
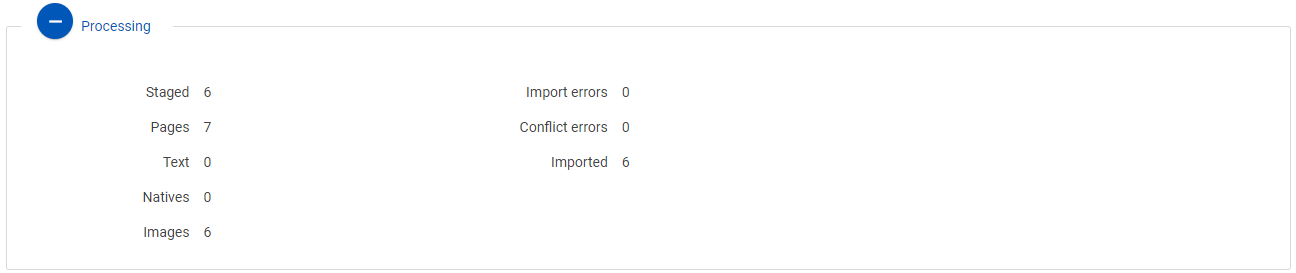
Processing
This shows counts of information such as documents staged and imported, pages imported, text imported, natives imported, documents with images imported, and any import errors that may have occurred.
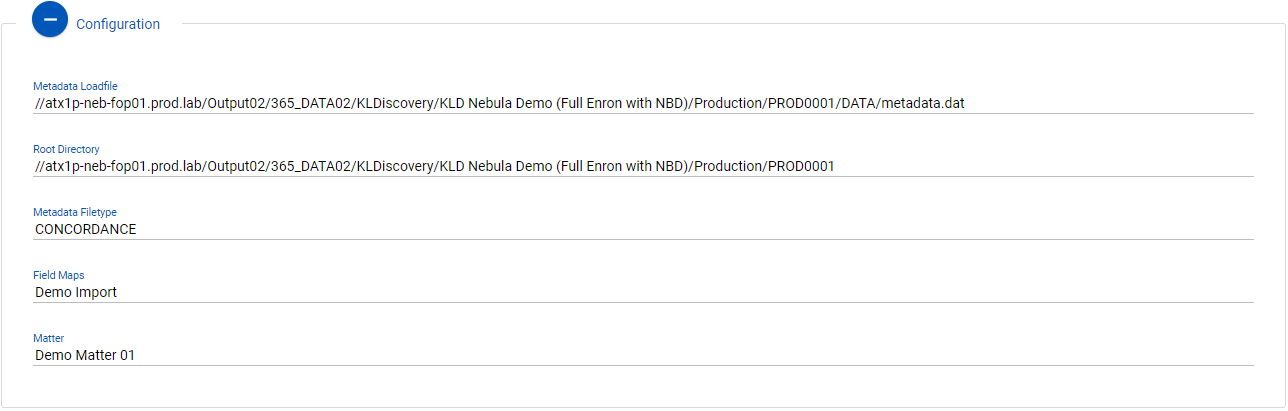
Configuration
This shows details regarding the configuration of the import.
Operations
This shows the status of post-import operations performed on imported content.

Overlay and Production imports contain the following information:
Processing
This shows counts of information such as documents staged and imported, pages imported, text imported, natives imported, documents with images imported, and any import errors that may have occurred.
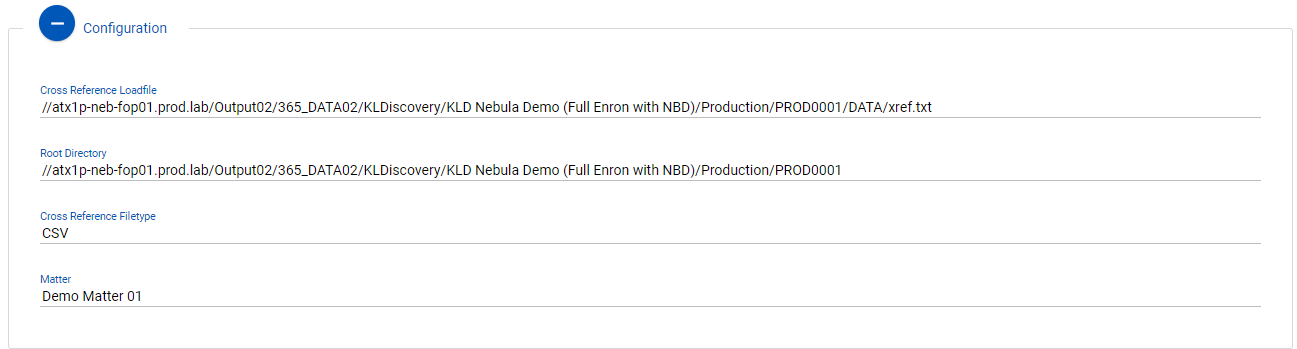
Configuration
This shows details regarding the configuration of the overlay.
To reprocess an import collection
- On the Processing Details page, click Reprocess.
- On the Upload Files page, click Restart.
To generate a report for an import collection
- On the Processing Details page, click Reports.
- On the Create Report dialog box, select the Report Type you want to generate:
- Exclusion Report: Summary of documents that were not imported, usually because they were duplicates or did not meet minimum requirements.
- Exception Report: Summary of documents that did not process due to an issue with the file.
- OCR Report: Summary of documents of OCR’d due to the RUN option.
- Click CSV.