Predictive Coding
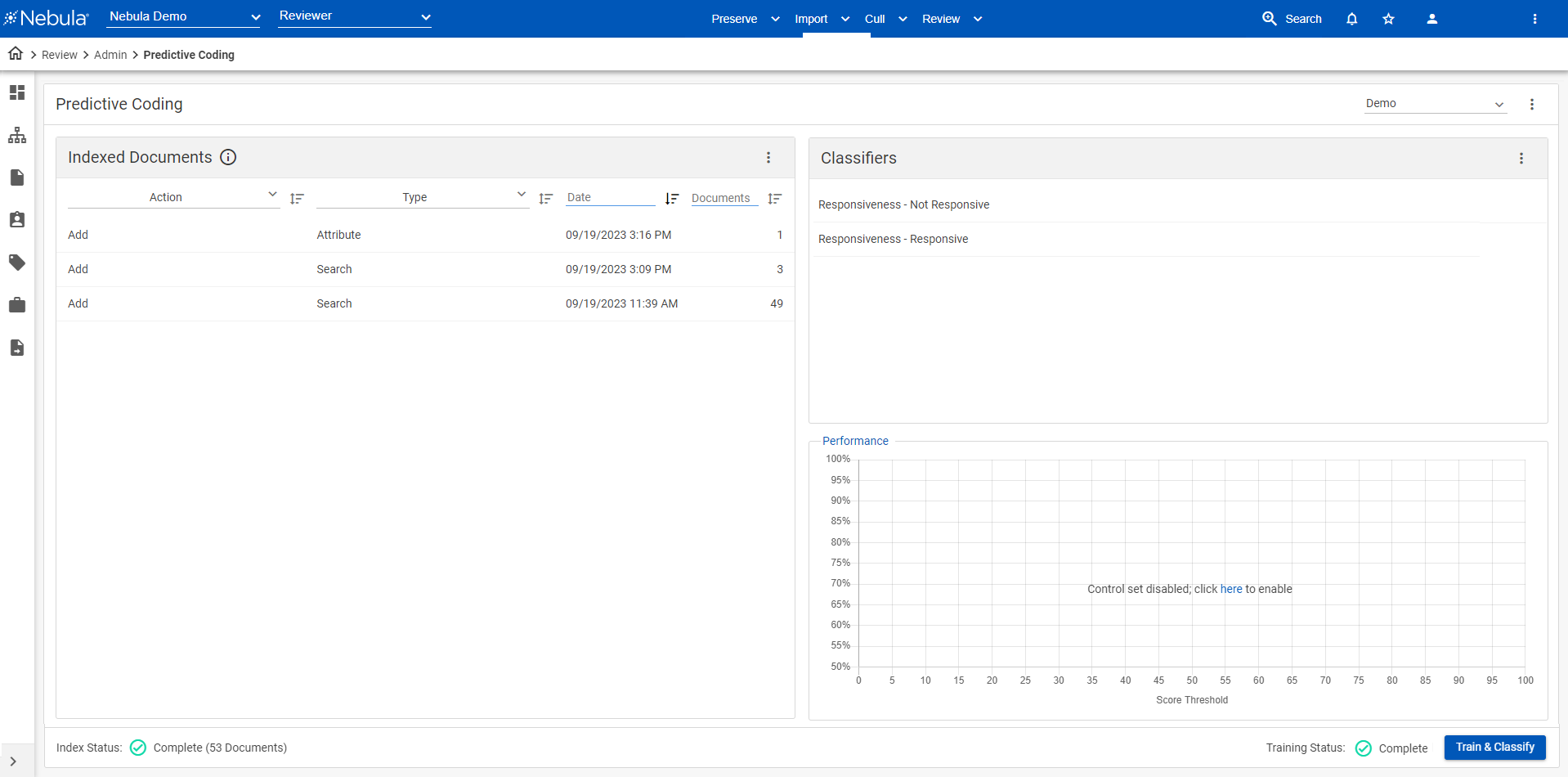
Predictive Coding leverages reviewer coding decisions across a document collection to create a model for all documents. This is represented as a score, or ranking, between 0 and 100 for all documents. As reviewers code documents in Review, predictive coding analyzes the documents, generates scores, and prioritizes the remaining documents for review based on similar attributes using Continuous Active Learning (CAL) in terms of likelihood of responsiveness.
With predictive coding, you can:
- Increase the priority of responsive documents.
- Decrease the priority of non-responsive documents.
- Review the documents until reaching a zero percent responsiveness rate.
Predictive coding uses persistent indexing to reduce the processing time required for training and classifying sessions. Indexing automatically occurs in new predictive coding projects when documents are added from the Reviewer Document List, as well as when additional documents are added to an existing predictive coding project.
The Control Set feature enables you to check the model quality and view the results of the predictive coding, as well as download predictive coding classifier performance metrics for various score thresholds.
Predictive coding projects are handled by KLDiscovery's EDiscovery Technologist (EDT) team who consult with clients on its use.
For more information, see:
To view the Predictive Coding page
- In the Nebula menu bar, click Review > Admin > Predictive Coding.