Near-duplicate Detection
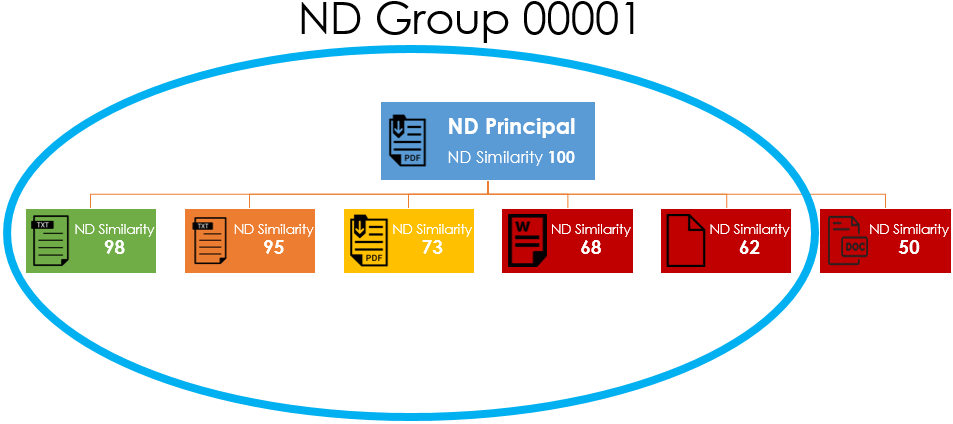
Near-duplicates in Nebula compares to content of documents within the same group, then gathers similar documents into near duplicate groups. A document that is most similar to all the others is identified in each group. This document is the Near Duplicates Principal (NDP). Every Near Duplicate Group will have its own NDP.
Documents within the near duplicate groups are compared to the NDP and given a Near Duplicates (ND) Similarity score. Documents above a similarity score threshold (such as a level 60 as displayed in the following diagram) are included in the near duplicate groups.
Note: While Near-duplicates can be used with emails, it is not recommended, as emails share so much content as header information (To, From, CC, BCC, and so on). Email threading is a better solution for email file types and their attachments.
To create a Near Duplicates Set
- Create a saved search of the documents to be checked for Near Duplicates (usually .doc, .ppt, or .txf files) or select an existing document grouping from the Review Explore menu.
- On the Document List menu, click the Action icon
 and select Run Text Analytics.
and select Run Text Analytics. - On the Create New Analytics Set dialog box, click Near Dups.
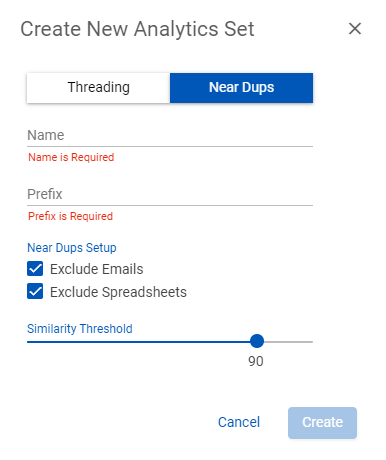
- Enter the Name and Prefix of the near duplicate set.
- In the Near Dups Setup section, Exclude Emails and Exclude Spreadsheets are select by default. Clear the checkboxes to include.
- Select the Similarity Threshold (a value from 50 to 100). This is the percentage of content a document must share with Principal document to be considered a duplicate. If a document’s percentage is beneath the similarity threshold, it is excluded from the Near Duplicate Group.
- Click Create to run the Near Duplicates algorithm runs across the document set.
To track the status of the analytics set, on the Manage menu, select Admin > Tasks.
Note: By default, Threading is active. If email threading is not in use for this document set, clear Threading.
Note: Near Duplicates is quicker when Excel documents and emails are excluded. Consider using Email Threading for email files. For more information, see Email Threading.
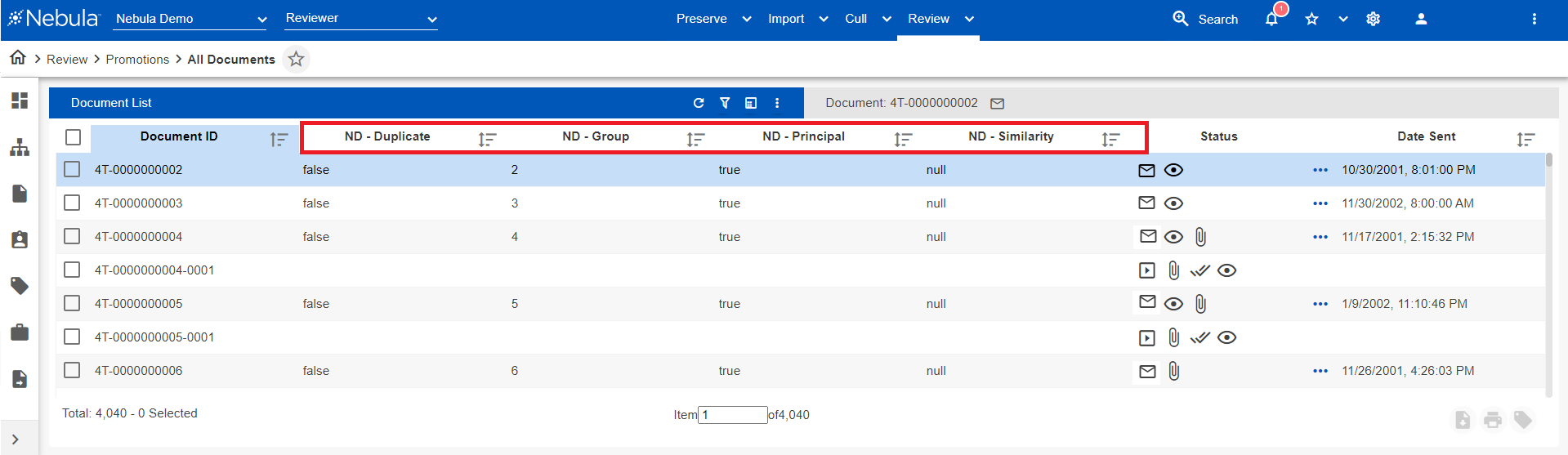
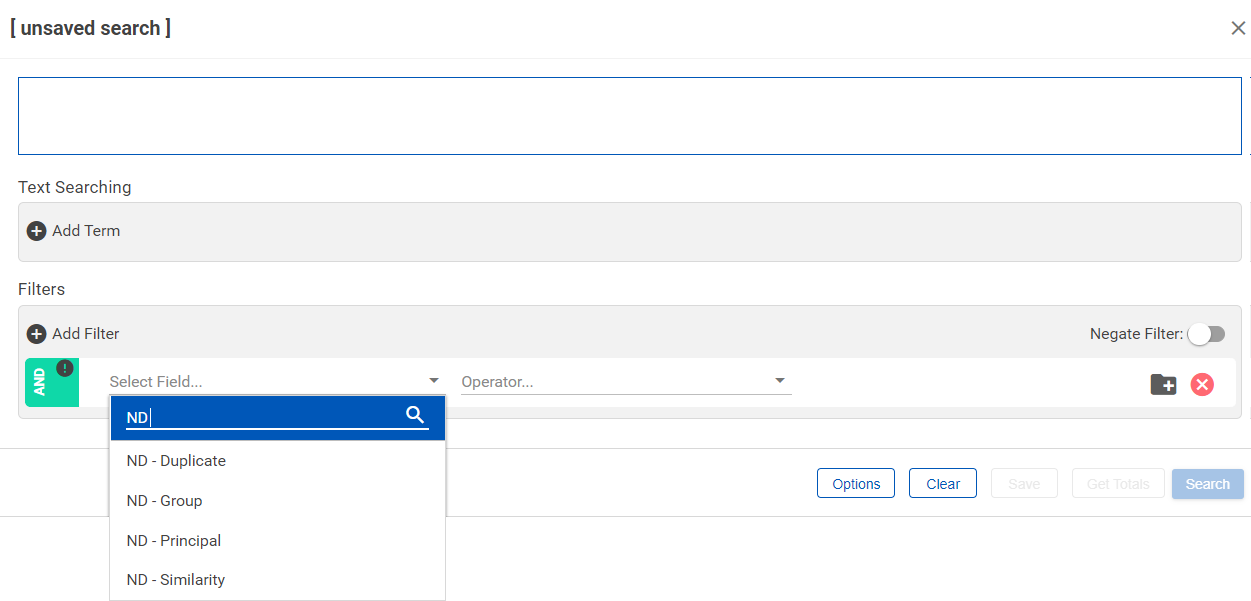
After processing a Near Duplicate Set, the following document fields are available in the matter:
| Field | Contents |
|---|---|
| ND - Group | A unique, relational field shared by all documents in the same group (similar to a family ID). |
| ND - Principal | A Yes/No field indicating if the document is the Near Duplicate Principal (NDP) in a Near Duplicate group. |
| ND - Similarity | The similarity threshold score indicating the percentage of similar content with the NDP. |
| ND - Duplicate | A True/False field noting MD5 duplicates of the Near Dups Principal document. |
Using Near Duplicates in Review
You can add the fields to a view ...
... create searches that include near duplicate documents using Filter searches ...
... or view related items in the Related section of the Coding pane.